DETR是第一个end2end的目标检测器,不需要众多手工设计组件(anchor,iou匹配,nms后处理等),但也存在收敛慢,能处理的特征分辨率有限等缺陷。原因大概存在如下:
- transformer在初始化时,分配给所有特征像素的注意力权重几乎均等;这就造成了模型需要长时间去学习关注真正有意义的位置,这些位置应该是稀疏的;
- transformer在计算注意力权重时,伴随着高计算量与空间复杂度。特别是在编码器部分,与特征像素点的数量成平方级关系,因此难以处理高分辨率的特征;
Deformable DETR的工作就在于解决DETR收敛慢以及高计算复杂度问题。具体做法有:
多尺度特征 & 多尺度Embedding
在DETR中,由于计算复杂度的问题,仅仅只使用了单尺度特征,对于特征点位置信息编码使用三角函数,不同位置对应不同编码值。而在多尺度特征中,位于不同特征层的特征点可能拥有相同的(h,w)坐标,使用一套位置编码是无法区分。因此作者使用多尺度特征时,增加了scale-level embedding,用于区分不同特征层。不同于三角函数使用固定公式计算编码,scale-level embedding是可学习的。
1 | class DeformableTransformer(nn.Module): |
Deformable Attention
通俗地来讲,可变性注意力即,query不是和全局每个位置的key都计算注意力权重,而仅在全局位置中采样部分位置的key,并且value也是基于这些位置进行采样插值得到,最后将局部&稀疏的注意力权重施加在对应的value上。
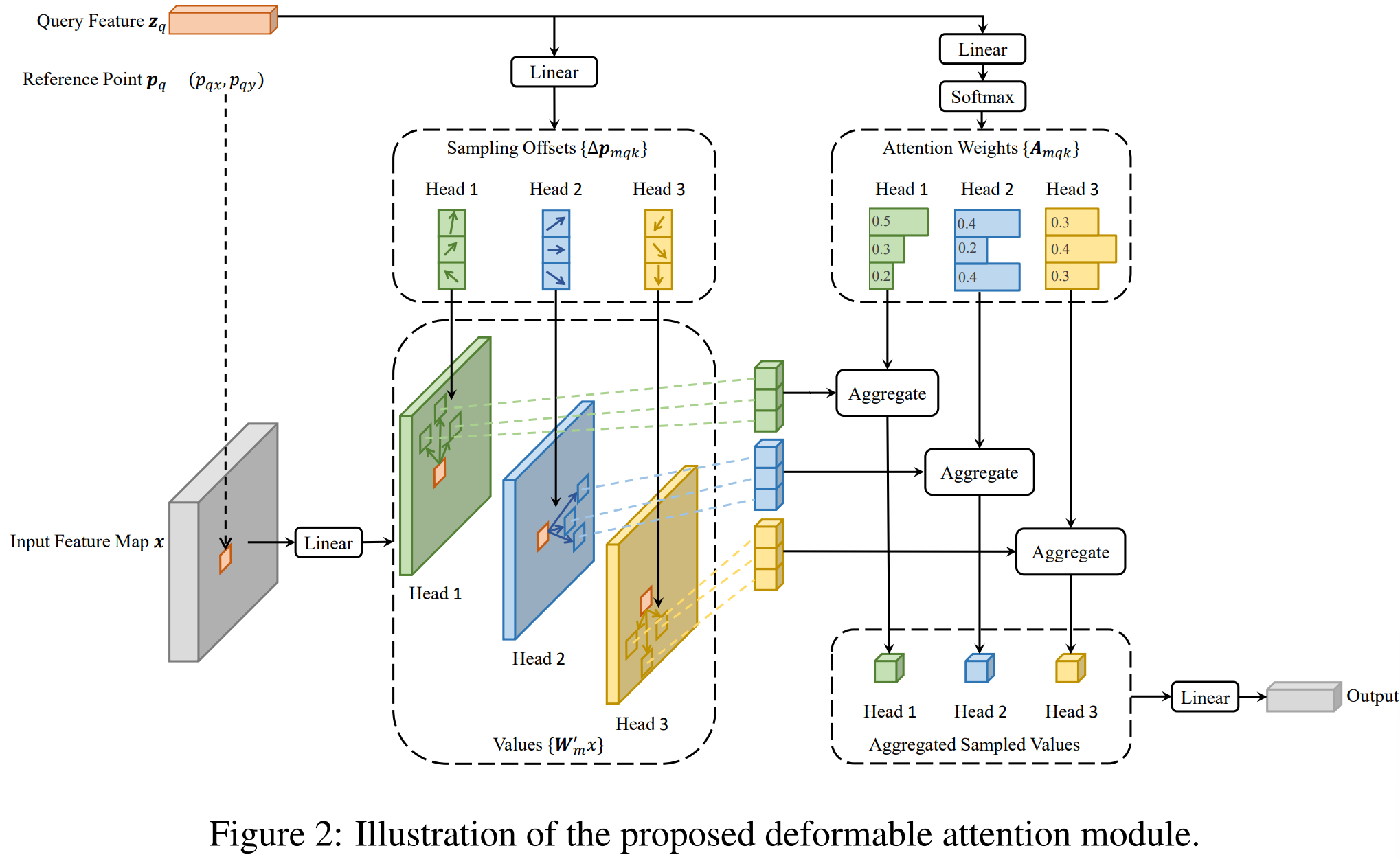
如上图所示,每个query在每个head上采样K个位置,只需和这些位置的特征进行交互,不同于detr那样,每个query需要与全局位置进行交互。需要注意的是,位置偏移量$\Delta p_{mqx}$ 是由query经过全连接得到的,注意力权重也是由query经全连接层得到的,同时在K个采样点之间进行权重归一化。
1 | class MSDeformAttn(nn.Module): |
Deformable Transformer
与DETR大体一致,主要区别在于用Deformable Attention替换了Encoder中的self-attn和Decoder中的cross-attn。
Encoder前处理
1 | class DeformableTransformer(nn.Module): |
在DeformableTransformer的前向处理过程中,首先会对多尺度相关的元素进行flatten,这些输入元素包括:多尺度特征图、各尺度特征图对应的mask(指示哪些部分属于padding)、各尺度特征图对应的位置信息(position embedding + scale-level embedding),另外还有些辅助信息,比如:各尺度特征图的宽高、不同尺度特征对应于被flatten的那个维度的起始索引、各尺度特征图中非padding部分的边长占其边长的比例。
Encoder编码
经过Encoder前处理之后的信息就会经过Encoder进行编码,输出memory。下面代码展示的是Encoder的处理过程:
1 | class DeformableTransformerEncoder(nn.Module): |
输出memory(编码后的特征表示),shape是 (bs, h_lvl1w_lvl1+h_lvl2w_lvl2+.., c=256),其中h_lvli和w_lvli分别代表第i层特征图的高和宽,于是第二个维度就是所有特征点的数量。编码后,特征的最后一个维度hidden_dim=256.
Decoder前处理
对encoder的输出进行处理,得到参考点reference_points,需要说明下,在2-stage模式下,参考点和输入到Decoder的object query及query embedding的生成方式和形式会有所不同。
1 | class DeformableTransformer(nn.Module): |
- 如果是two-stage 模式下,参考点由Encoder预测topk得分最高的proposal box(这时的参考点是4d,bbox形式),然后对参考点进行position embedding来生成Decoder需要的object query和对应的query embedding;
- 非two-stage模式下,Decoder的 object query(target )和 query embedding 就是预设的embedding,然后将query embedding经过全连接层输出2d参考点,这时的参考点是归一化的中心坐标形式。
另外,两种情况下生成的参考点数量可能不同:2-stage时是有top-k(作者设置为300)个,而1-stage时是num_queries(作者也设置为300)个,也就是和object query的数量一致(可以理解为,此时参考点就是object query本身的位置)。
Decoder解码
这里与Transformer中主要的区别在于使用可变形注意力替代了原生的交叉注意力。类似地,每层的解码过程是self-attention+cross-attention+ffn,下一层输入的object query是上一层输出的解码特征。
1 | class DeformableTransformerDecoder(nn.Module): |
进行Decoder解码完之后就是接class_embed和bbox_embed得到最后box分数和坐标。在上面需要注意的一点是,每次refine后的bbox梯度是不会传递到下一层。
总结
- 相比于DETR,使用了多尺度特征+scale-level embedding,用于区分不同特征层;
- 使用了多尺度可变形注意力替代Encoder中的selfattn和Decoder中的crossattn,减小计算量;
- 引入了参考点,类似引入先验知识;
- 设计了两阶段模式和iteraitive box refinement策略;
- 检测头回归分支预测是bbox相对参考点的偏移量而非绝对坐标值;